Azure: 이미지를 아스키 문자로 변환하기② - Custom Vision 트레이닝
</br>
전 편에 이어서~~
</br>
이미지 데이터 등록
문자들 이미지는 100*100으로, 폰트는 간격이 모두 같은 Courier, BOLD로 했다.
프로젝트 생성 후 화면이다. Add images 버튼으로 이미지를 추가해 보자!! 좌측 상단의 + 네모 버튼도 가능하다.
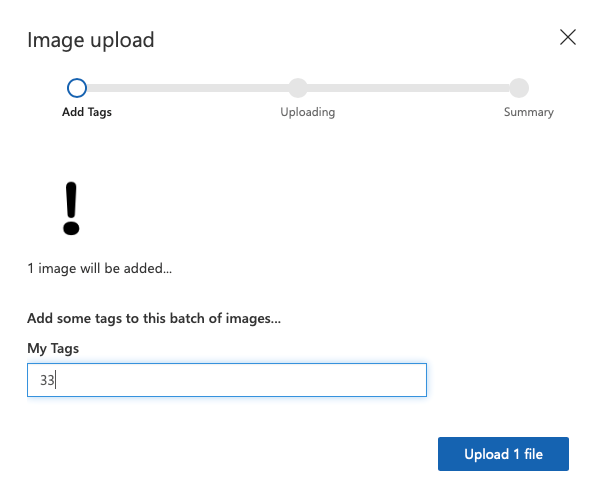
이렇게 사진을 올리고, 태그를 붙인다. !는 아스키 코드 33이므로 그렇게 붙였다.






한 장 씩 다 올린 모습
근데 트레이닝 하려면 적어도 2개의 태그, 태그 당 5장이 필요하대서 조금씩 크기와 위치를 차이를 줘서 더 만들어 넣었다.
포토스케이프를 사용하면 일괄 편집이 아주 쉬워서 좋다
</br>
Training
Quick Training

우측 상단의 초록색 Train 버튼을 누르면 학습시킬 수 있다.
정확도는 좀 낮을 수 있지만 간단하고 빠르게 Quick Training으로 시험 해 보자.
그러면 이렇게 시작된다.
퀵은 주로 5분 이내로 되는 것 같더라
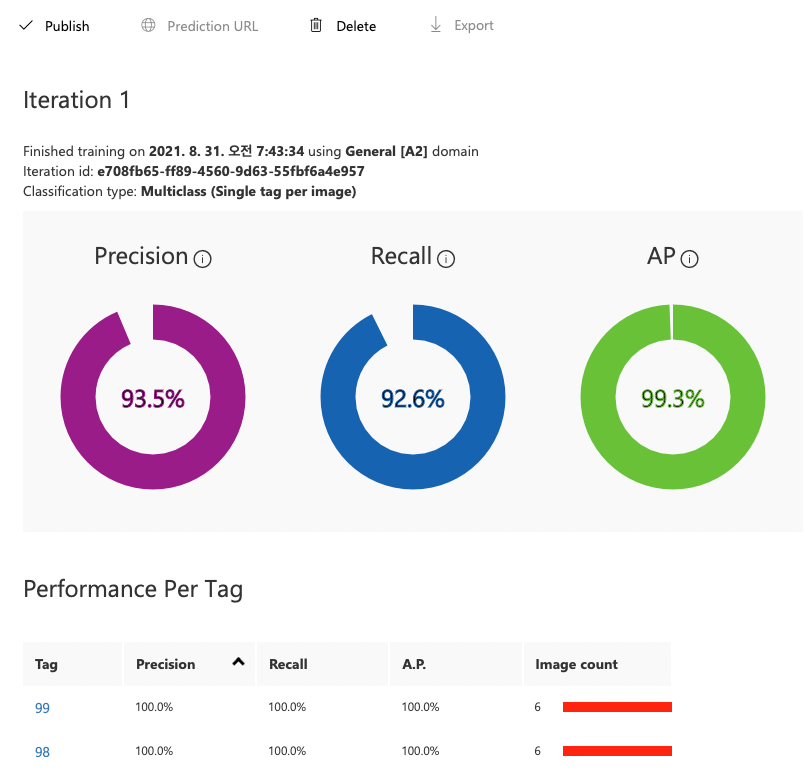
완료 되면 이런 화면이 뜬다!
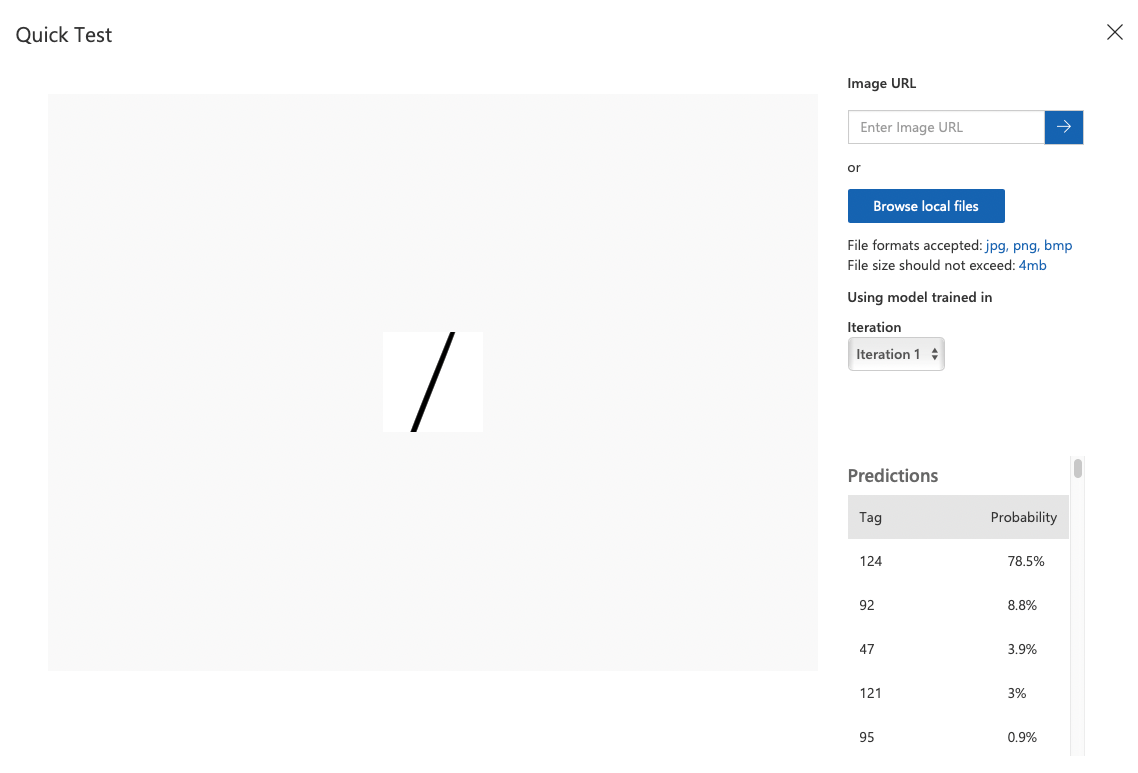
상단의 Quick Test 버튼으로 빠르게 테스트 해볼 수 있다.
선을 하나 그어서 이미지를 업로드해 검사해 본 결과, 124일 확률이 약 78%로 나왔다.
헉…나는 47인 /가 나오길 바라고 올린 건데 코드 124면 |다. 게다가 47보다 92가 예측 확률이 더 높은데, 92면 \로 반대 방향인데도 그렇네
아무래도 이미지도 6개 뿐이라 데이터 셋이 약하기도 하고, 퀵 트레이닝이라 더 부정확하기도 하다.
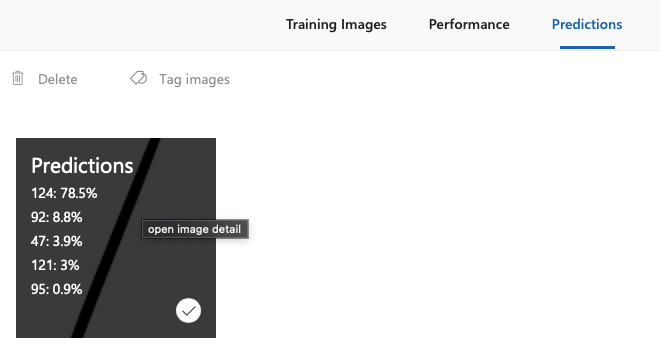
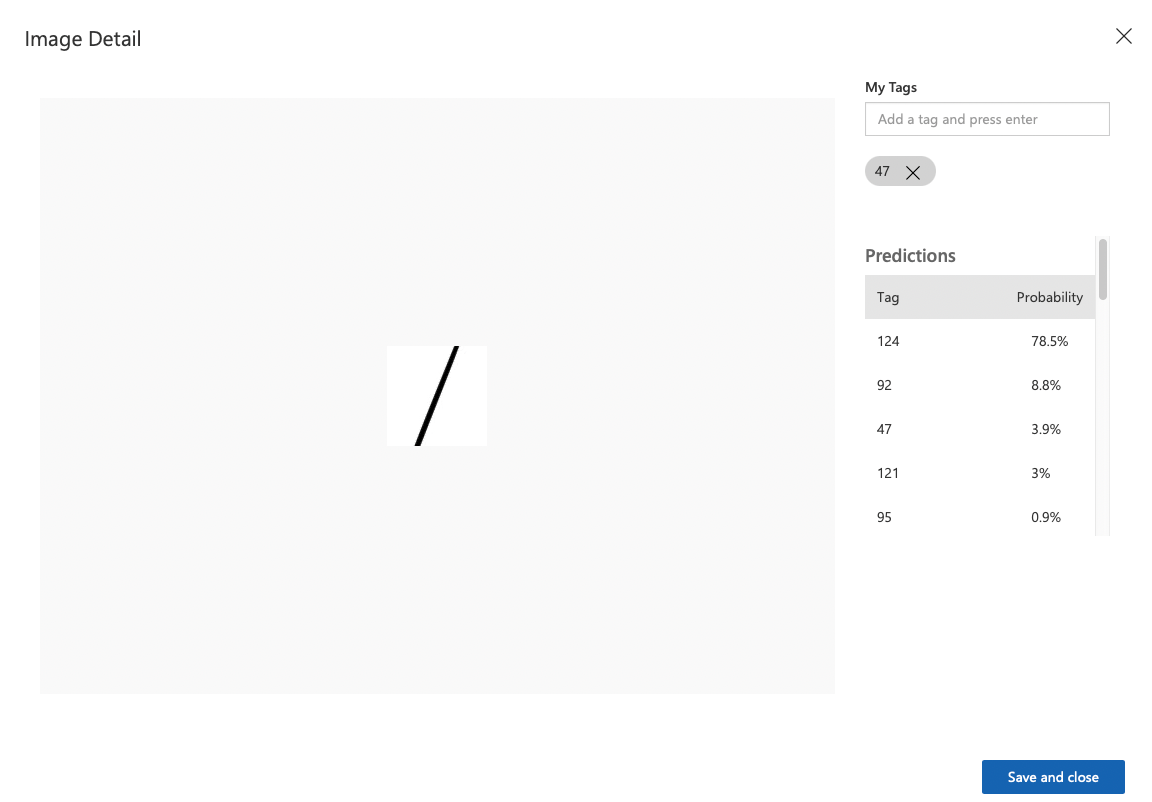
Predictions 탭에서 결과를 다시 볼 수 있다. 클릭하면, 태그를 붙이고 저장할 수 있다. 따라서 알맞은 태그인 47을 붙이고, Save and close한다.
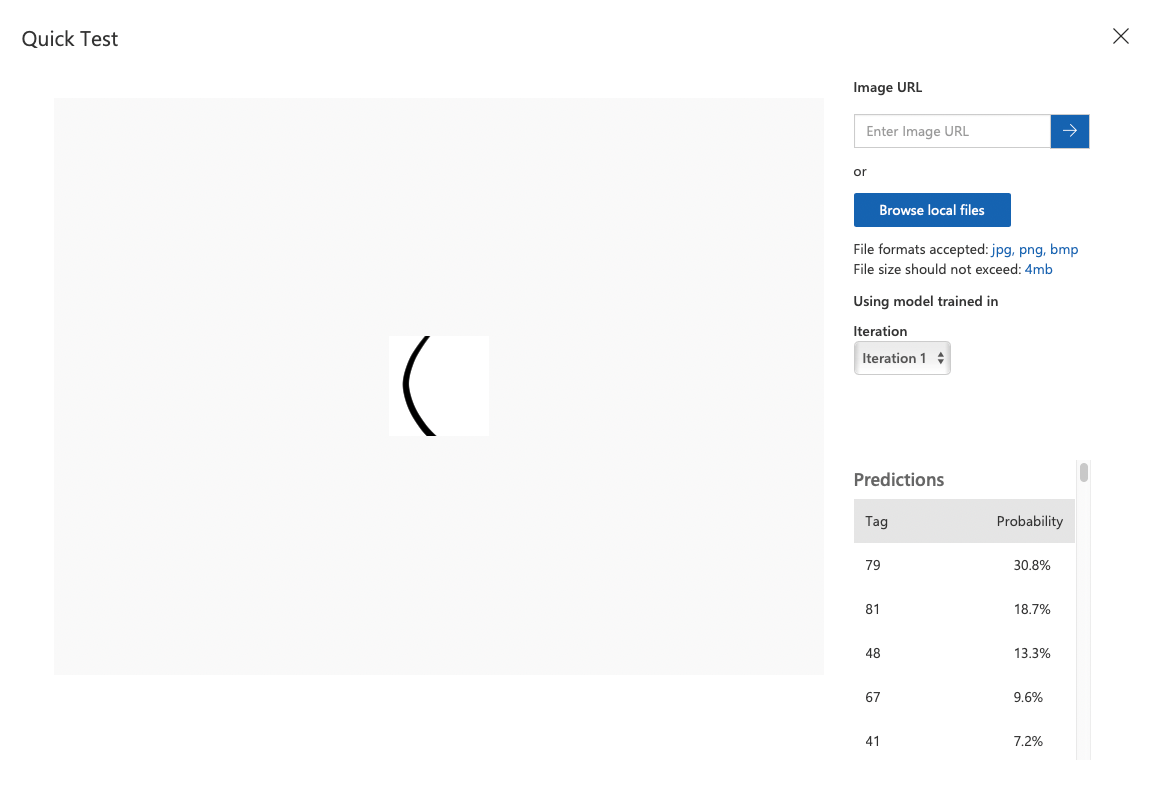
다른 결과로, 40번인 (를 노리고 만든 그림이다. 이번엔 79인 O라고 추측했다.
얘도 알맞은 태그를 붙여서 저장했다.
</br>
Advanced Training

방금 데이터들과 비슷한 걸 몇 장 더 넣고, 이번엔 Advanced Training을 선택해 보았다.
몇 시간 돌릴 지 선택하고, 끝나면 메일을 보내 달라고 요청할 수 있다.
1시간을 선택하고, 잠시 책을 읽었다.
</br>
책: 좀 이상하지만 재미있는 녀석들
(저넬 셰인 지음)
도서관에서 빌렸다 재밌음

대충 이해한 바로 적자면, AI는 문제를 제대로 이해하고 수행하는 게 아니라 규칙을 스스로 설립하고 확인하고 수정하는 일을 한다.
일례로 저자가 사진을 넣으면 뭐가 있는 지 구분해주는 AI를 훈련시켰는데, 이상하게 양이 없는 사진에서 계속 양이라고 태그가 붙었다.
알고 보니까 양 태그의 학습 데이터 셋에는 푸른 들판에 있는 양들 사진들밖에 없어서, AI는 푸른 들판을 양으로 규정해 버렸고, 어느 사진에서 푸른 들판이 감지 되었다면 양이라고 태그를 붙였다고 한다.
비슷하게 자동차 안에 양을 합성해서 넣어도, AI는 대충 자동차 안의 북슬북슬한 무언가라고 인식해서 고양이라고 답을 낼 수도 있다. AI는 양이 뭔지 모르기 때문이다!
또 비슷하게, 스탠퍼드 대학에서 건강한 피부와 피부암 사진을 구분하는 AI를 훈련시켰는데, 종양 사진에는 눈금자가 존재했기 때문에, 이 AI는 눈금자가 많다면 피부암이라고 구분해 버렸다고 한다ㅋㅋ
</br>
Advanced Training(1시간) 결과
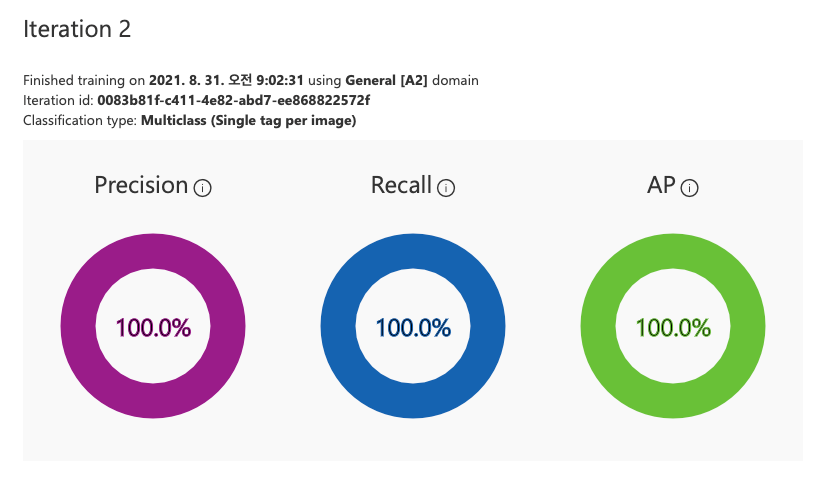
성능이 좀 나아졌을까
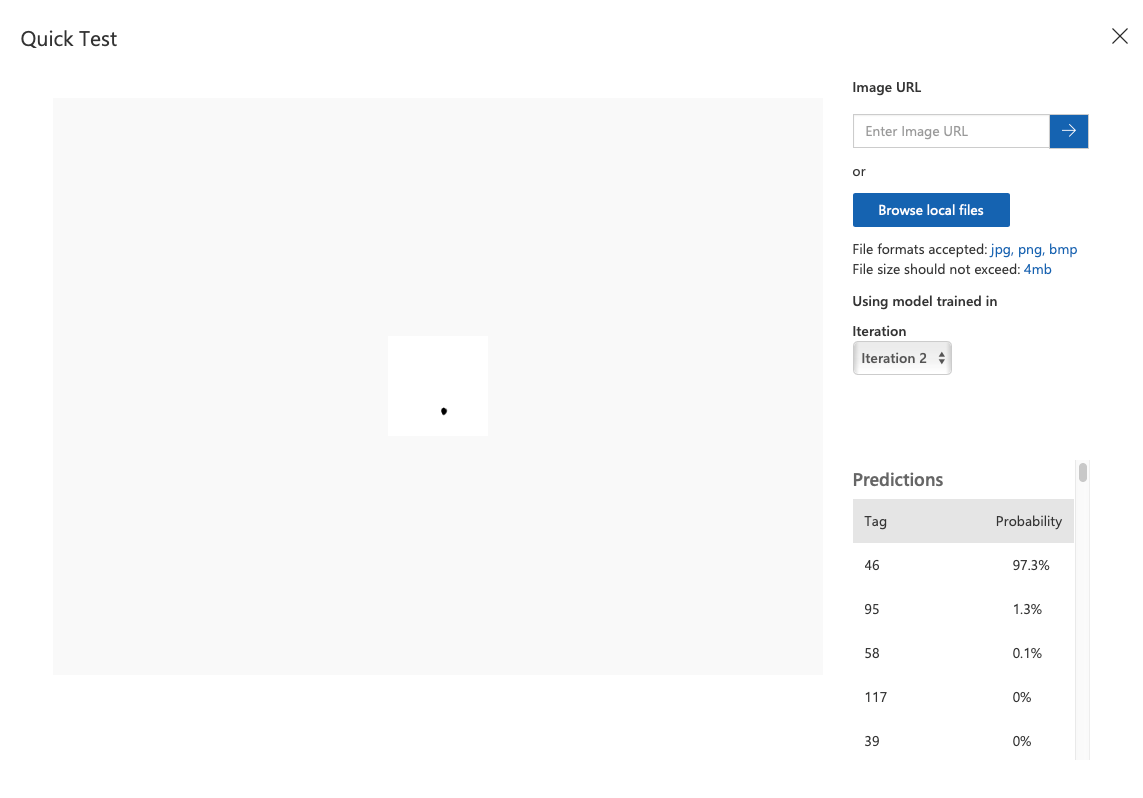
이번엔 코드 46인 .을 노리고 한 번 넣어 봤다. 다행히도 97.3%로 46일 거라고 예측했다.
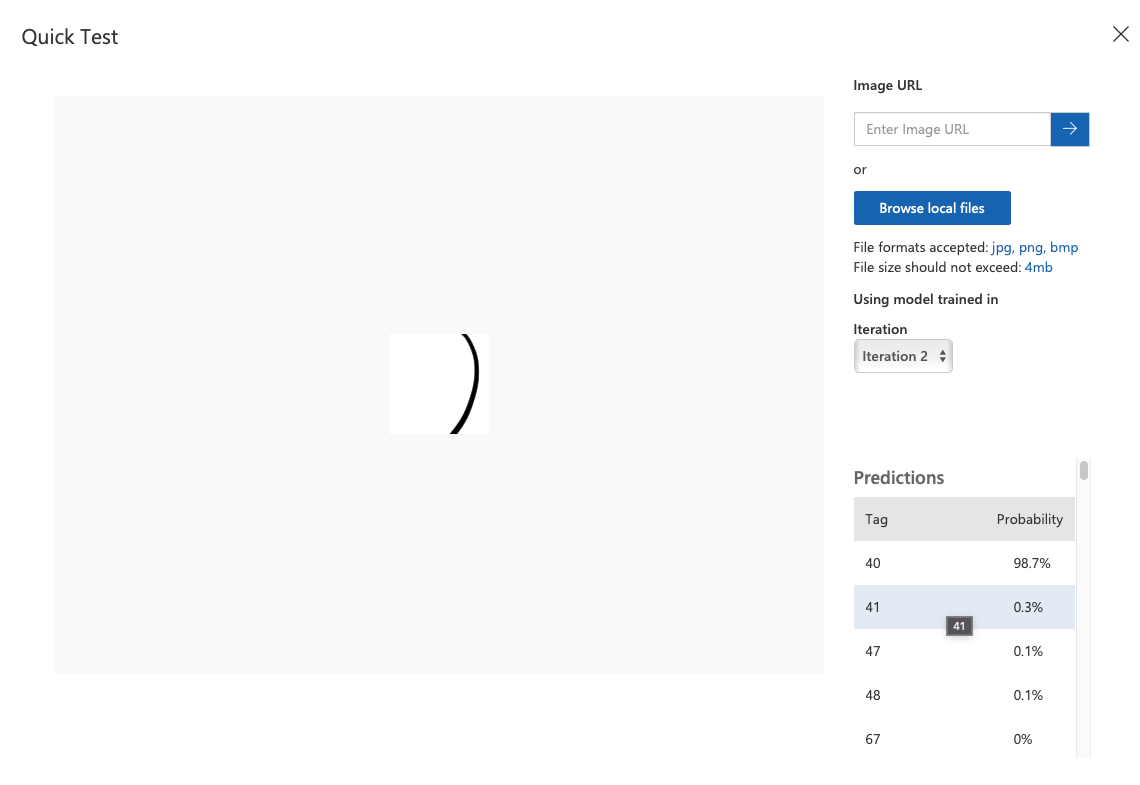
헉… 얘는 코드 41인 )가 나왔으면 좋겠는데, 40번인 (일 확률이 98.7%란다 아이고
아무래도 이 AI는 대충 휘었으면 태그 40으로 결론 짓자고 규칙을 지었나 보다

다른 것들도 넣어본 결과, 확실히 처음의 Quick Training 보다는 나은 결과가 나오지만, 애초에 데이터가 몇 장 없어서 그런지(거의 비슷한 것들 7장 이내였다) 별로다.
일단 또 몇 장을 더 추가하고, 이번엔 2시간 짜리 Advanced Training을 시작했다.
오늘은 새벽에 일어나서 책 잠시 또 보다가 낮잠을 잤다
Advanced Training(2시간) 결과
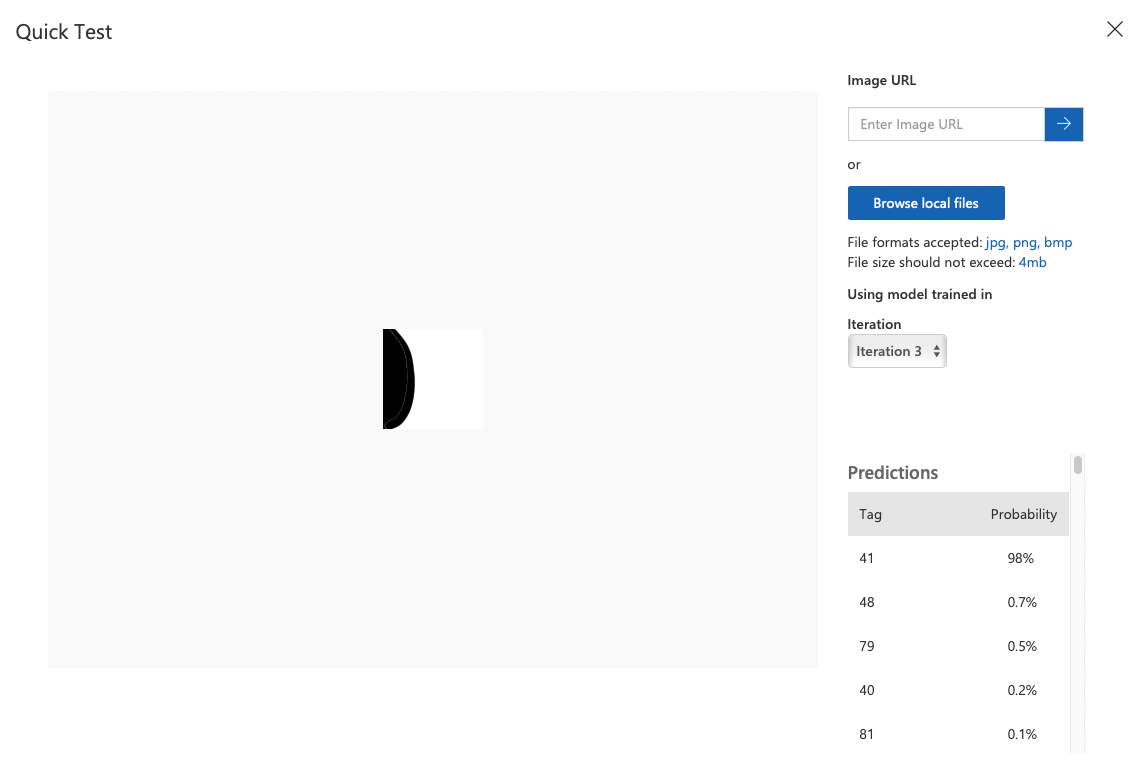
코드 41인 )가 잘 나옴
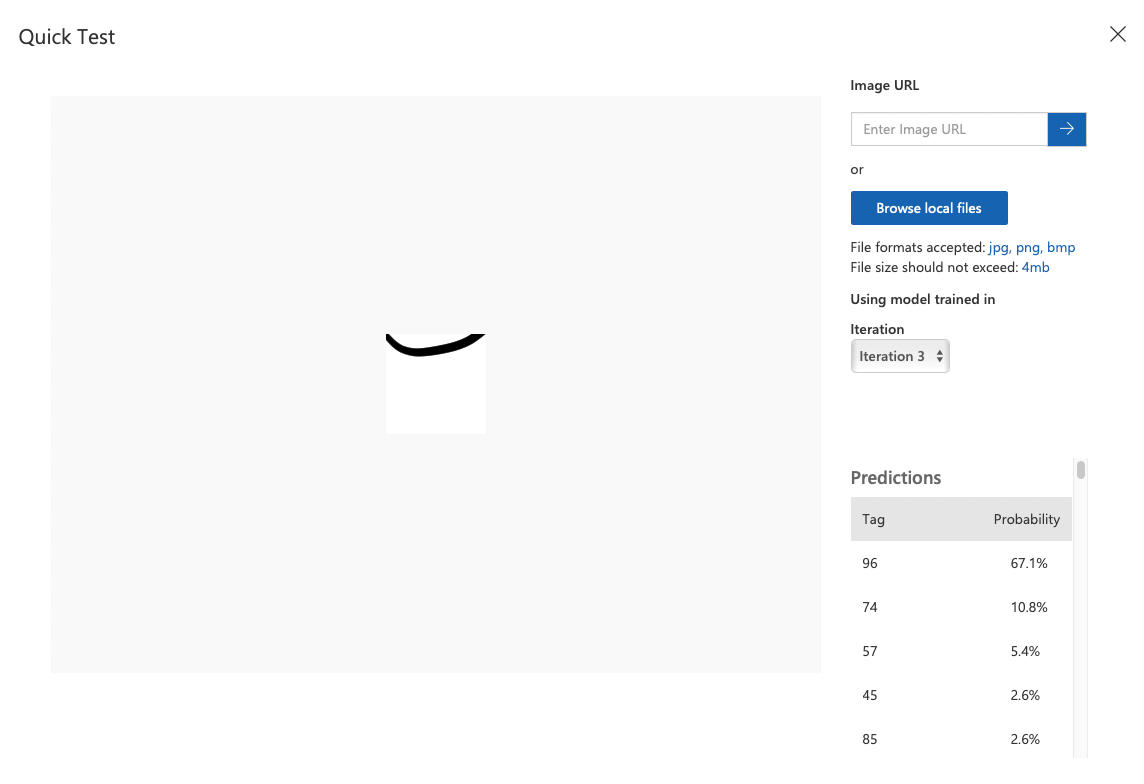
대충 넣어 본, 딱히 닮은 ASCII 문자가 없는 애매한 이미지
코드 96일 확률이 67.1% 정도인데, 96번은 `다. 괜찮은 듯
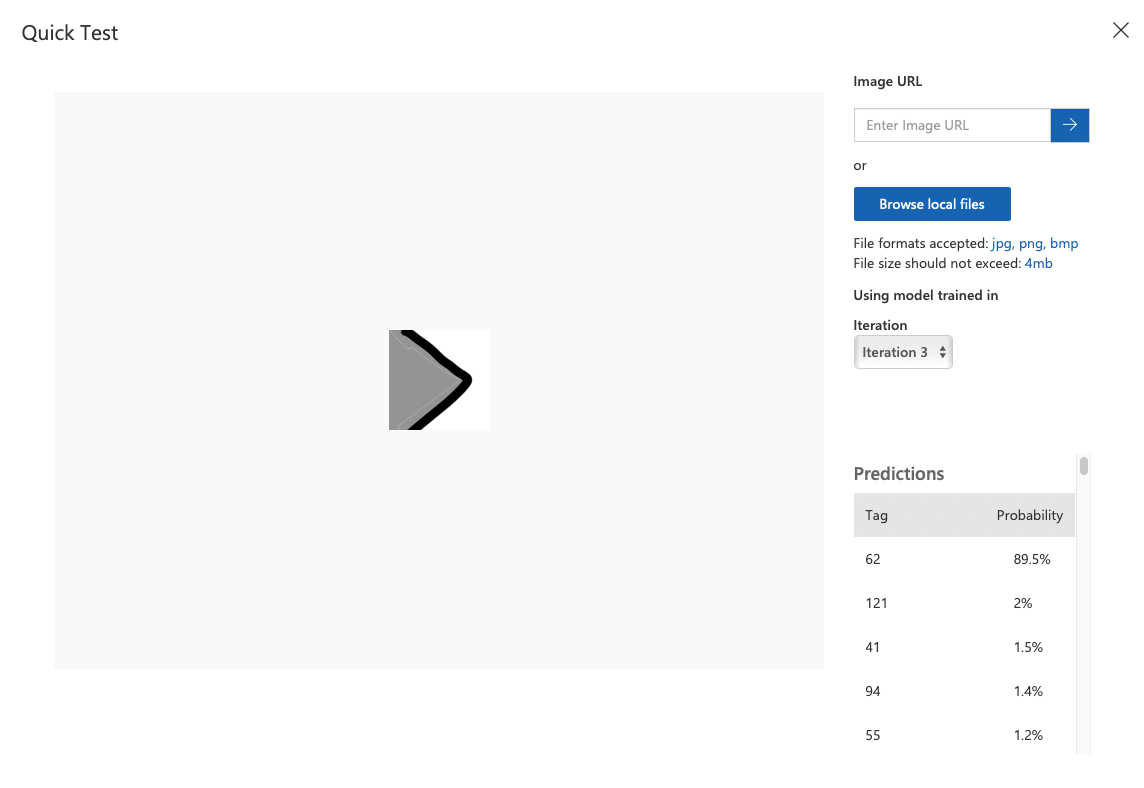
코드 62인 >을 생각하고 넣어 봤는데 괜찮게 잘 나온다.
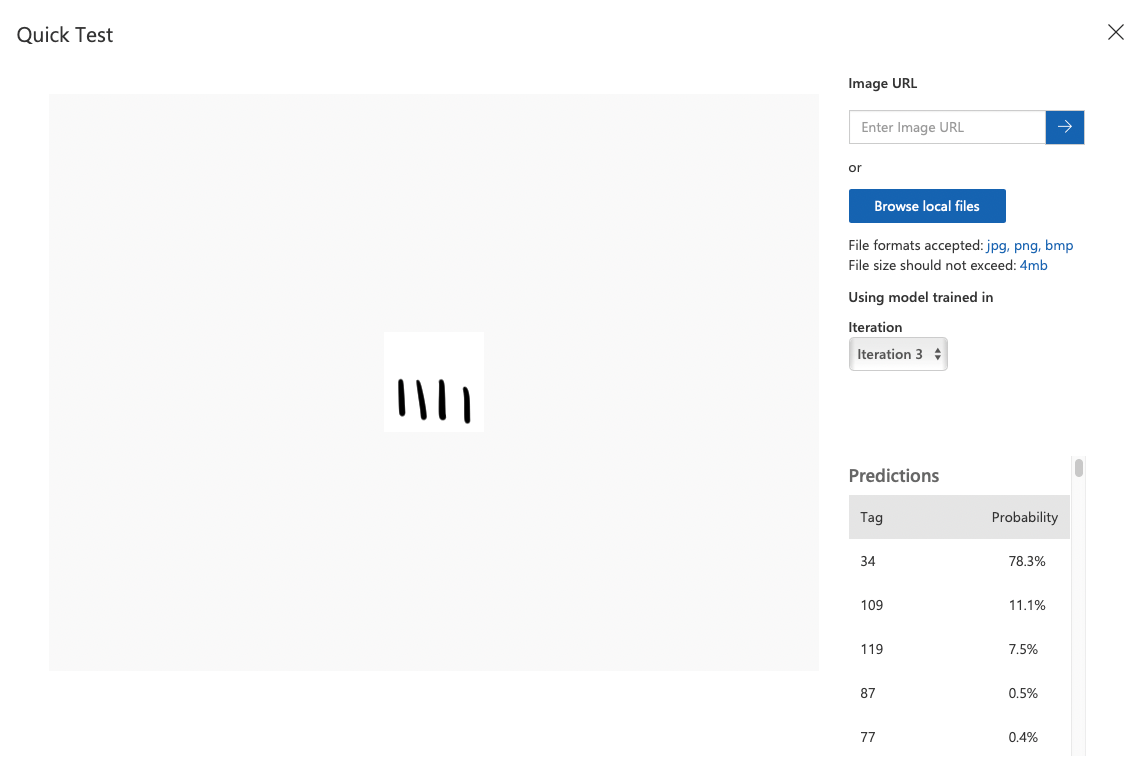
이것도 좀 닮은 게 없는 애매한 이미지
34, 즉 "일 확률이 78.3%다. 나름 비슷하게 생겼으니 괜찮긴 한데, 아무래도 형태보다는 위치를 더 고려했으면 좋겠으므로 m이 나을 것 같다. 따라서 109로 태그를 달아줬다.



이외에도, 명암을 표시하기 위해 가장 진한 검정은 최대한 여백이 없는 문자인 @(64), 회색은 %(37), 연회색은 :(58)로 등록했다.
@@@@@@@ %%%%%%% :::::::
@@@@@@@ %%%%%%% :::::::
@@@@@@@ %%%%%%% :::::::
폰트나 환경 따라 좀 @와 % 여백의 느낌이 달라지긴 한다
</br>
필기 인식도 이런 느낌이겠지?? 각 글자마다 여러 사람들의 필기체를 데이터로 잔뜩 많이 넣고 학습시키면 될 것 같다
이런 몇 없는 헐빈~한 구린 데이터들과 2시간 학습으로 제대로 된 건 못 만들겠지만, 이제 다음 포스트에선 간단하게 앱으로 결과를 확인해 봅시다
</br>
댓글남기기