백준: Silver2④ - 1411: 비슷한 단어 (반례 찾아 보기, 랜덤하게 예제 생성)
</br>
얘는 처음에 그냥 보이는 대로 구현했다가 오답이 나왔다.
그래서 간단하게 다시 생각해서 푸니까 바로 정답 처리는 되었는데, 처음 코드가 어디가 틀린 건 지 한 번 찾아 보기로 했다.
</br>
1411: 비슷한 단어
https://www.acmicpc.net/problem/1411
두 단어가 있는데, 한 단어의 알파벳들을 바꿔서 같게 만들기
</br>
방법 1.
for(int i = 0; i < n; i++){
string s;
cin >> s;
memset(used, 0, 26*sizeof(int));
int k = 1, vv = 0;
for(int j = 0; j < s.size(); j++){
if( used[s[j] - 'a'] == 0 ){
used[s[j] - 'a'] = k;
vv = vv*10 + k;
k++;
}
else{
vv = vv*10 + used[s[j] - 'a'];
}
}
v.push_back(vv);
}
int cnt = 0;
for(int i = 0; i < n-1; i++){
for(int j = i+1; j < n; j++){
if( v[i] == v[j] ){
cnt++;
}
}
}
cout << cnt << endl;
처음 시도가 잘 안 돼서 간단하게 생각해 본 풀이다.
생각해 보니 사실상 알파벳 자체에는 의미가 없고, 어떤 조합으로 있는 지만 보면 됐다.
ex) aa -> 11, abc -> 123, aaf -> 112
이렇게 바꿔서 벡터에 저장해 준 후, 2개 조합을 이중 포문으로 구해 같은 지 비교만 하면 간단하게 풀린다.
</br>
방법 2.
int used[26];
int changed[50];
bool func(string s1, string s2){
for(int i = 0; i < s1.size(); i++){
if( s1[i] == s2[i] ){
if( used[s2[i]-'a'] == 0 ){
used[s2[i]-'a'] = 1;
for(int j = i+1; j < s1.size(); j++){
if( s1[j] == s1[i] ) changed[j] = 1;
}
}
else if( changed[i] == 0 ) return false;
continue;
}
if( changed[i] == 0 && used[s2[i]-'a'] == 0 ){
used[s2[i]-'a'] = 1;
for(int j = i+1; j < s1.size(); j++){
if( s1[j] == s1[i] ){
s1[j] = s2[i];
changed[j] = 1;
}
}
s1[i] = s2[i];
}
else return false;
}
return true;
}
처음 시도 때 만든 풀이 함수다. 사람이 푸는 것과 비슷하게 구현해 보았다.
used 벡터는 이미 사용된 알파벳, changed는 단어의 인덱스가 이미 바꾼 것임을 의미한다.
즉 used에 이미 있는 알파벳으로는 바꿀 수 없고, 현재 인덱스의 changed에 표시되어 있으면 두 단어의 문자가 달라도 바꿀 수 없다.
두 단어를 처음부터 확인한다.
- 만약 두 문자가 같다면, 해당 문자를 자기 자신으로 바꾸는 것이므로
used에 문자를 사용했음을 표시하고, 단어 내의 모든 같은 문자들의 인덱스를changed에 표시한다(바꾼 것이므로).- 만약 두 문자가 같은데, 이미
used에 해당 문자가 있다면 자기 자신으로 바꾸지 못하므로return false한다. - 만약 두 문자가 같고
used를 확인하니 이미 사용되었는데, 해당 문자가 바뀐 것이 아니라면 자기 자신으로 바꾸지 못하므로return false한다.
- 만약 두 문자가 같은데, 이미
- 만약 두 문자가 다르다면, 단어 내의 모든 해당 문자를 목표 문자로 바꿔 주고
used와changed에 표시해야 한다.- 만약 두 문자가 다른데 해당 자리가 이미 바뀐 문자라면, 더이상 바꿀 수 없으므로
return false한다. - 만약 두 문자가 다른데 목표 문자가
used에 있다면, 더이상 바꿀 수 없으므로return false한다.
- 만약 두 문자가 다른데 해당 자리가 이미 바뀐 문자라면, 더이상 바꿀 수 없으므로
대충 룰은 정말 다 적용한 것 같은데 자꾸 틀렸다고 나왔다. 그래서 반례를 찾아 보기로 했다.
</br>
예제 만들기
맞는 풀이도 갖고 있고, 아닌 풀이도 있으니 둘이 답이 다르게 나온다면 그게 반례일 것이다.
그래서 적당히 아무렇게나 자판을 쳐서 나오는 대로 했는데 다 맞게 나와서, 예제를 제대로 만들어 보기로 했다.
int a = 1000;
while( a ){
ofstream out;
out.open(to_string(a)+".inp");
random_device rd;
mt19937 gen(rd()+a);
out << 100 << endl;
uniform_int_distribution<int> dis(0,25);
uniform_int_distribution<int> dis2(1,50);
for(int i = 0; i < 100; i++){
int m = dis2(gen);
string s;
for(int j = 0; j < m; j++){
s += dis(gen) + 'a';
}
out << s << endl;
}
a--;
out.close();
}
처음에 100개 만들었는데 또 다 맞게 나와서 1000개 만들었다. 그러니까 틀린 예제들이 나왔다.
문제 조건이 ‘단어의 길이는 최대 50이고, N은 100보다 작거나 같은 자연수, 알파벳 소문자로만 이루어짐’이므로, 쉽게 만들 수 있겠더라.
random_device rd;
mt19937 gen(rd());
uniform_int_distribution<int> dis(0,25);
uniform_int_distribution<int> dis2(1,50);
int m = dis2(gen);
이렇게 랜덤한 수를 얻을 수 있다. dis()는 범위를 나타낸다. 알파벳이므로 0 ~ 25(+’a’)이고, 단어의 길이가 최대 50이므로 이렇게 설정했다.
이후 for문에서 문자열을 랜덤한 길이로 100개 만들어 out에 적고 끝내기를 1000번 반복한다.
// a.inp
100
pgwvxzeztltppuuqksiarhxbswmjmrlgnjzapje
sfyinxmaqbrqhwbautnvfbpronlmnyradgcsvihhqspxrghl
gcjnpbuhbcrooqdmcsgfdzyerzgnocoh
evlk
daenmmsuzawtmzcexdjefa
kdegbpzojyalodutoflezlnixzqdcvlrfckcqzjfaczh
qaopspzvhtgxvufkridlfgbxtfeidffohjaxgq
btmfeptxzozjiazvtvaccekvvowjadfcno
smyqtfjbtsbj
sw
hyltbghtuhqhttmrlhwehcvmevairprejiwssnpwivthnanq
wmwy
a
.
.
.
그럼 대충 이런 게 1에서 1000까지 .inp가 만들어 진다.
지금은 7월 25일인데 포스트들이 밀려서 이 포스트는 언제 올라갈 지 참
</br>
답 비교
이제 답을 비교해 보자.
일단 맞는 풀이로 a.inp 파일을 읽어, 답을 출력하는 a.out 파일을 만들도록 했다.
이후 틀린 풀이로 a.inp 파일을 읽고, a.out 파일을 또 읽어 답을 비교하고, 틀린 답이 있다면 해당 예제 번호와 정답, 오답을 출력한다.
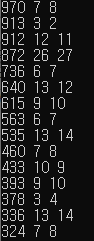
1000개에 15개 정도 나왔다. 으악
그런데 보니까 답이 적게 나온 것도 있고 많게 나온 것도 있다. 빠진 경우가 2가지인가 보다. 그래서 한 번 돌려서 단어들을 직접 확인해 보니…
2
hprjyxh rzdakid
2
ursdum srkfsc
이런 두 예제가 문제더라.
// in func()
if( changed[i] == 0 && used[s2[i]-'a'] == 0 ){
used[s2[i]-'a'] = 1;
for(int j = i+1; j < s1.size(); j++){
// if문 조건에 changed[j] == 0 추가!!
if( s1[j] == s1[i] && changed[j] == 0 ){
s1[j] = s2[i];
changed[j] = 1;
}
}
s1[i] = s2[i];
}
else return false;
최종적으로 고친 코드다. changed[j] == 0 이거 하나 추가하니까 잘 돌아간다…!!!
전에는 저 조건이 없어서, 이미 바뀐 자리의 알파벳인데 또 바꿔 버려 답이 이상하게 나와 버린 거다.
백준에 제출하니 맞았다고 나온다.
</br>
물론 포스트 가장 처음 나온 방법 1이 정말 간단하고 좋지만, 문제가 더 복잡해 진다면 이런 구현 방식도 필요할 지도 모른다.
또, 틀린 코드에 왜 틀렸는 지 디버깅하는 것도 중요하다고 생각하기 때문에 한 번 해 봤다.
간단한 조건 하나 빠뜨려서 이러니 좀 어이없긴 한데… 역시 덜렁대면 몸이 고생하는 거라는 교훈도 얻었다
알고리즘 풀 때나, 다른 때에도 생각하는 거지만 언제나 컴퓨터처럼, 컴퓨터 입장에서 생각하자!!!!!
</br>
댓글남기기